Local LLM vs. Cloud LLM
for AI-Driven Options Trading
A comprehensive research-backed analysis of architecture decisions for a custom options trading bot — covering latency, cost, privacy, multi-model design, and hardware optimization for a dual-node AMD + RTX 3090 setup.
Executive Summary
This report provides an independent, research-backed analysis of the architectural decisions facing the development of a custom AI-driven options trading bot. The central question — whether to rely on a locally hosted large language model (LLM) or a cloud-based API service — is evaluated across five critical dimensions: latency, cost, data privacy and security, performance and capability, and operational resilience.
Beyond the binary local vs. cloud decision, this report evaluates the multi-model agent pattern — deploying a hierarchy of specialized models rather than a single monolithic LLM — and finds strong empirical and theoretical support for this approach. Specific model candidates, inference engine recommendations, hardware budgeting, and safety control mechanisms are discussed in detail.
Hardware Overview
Dual-node AMD system with RTX 3090 GPU allocation
| Node | Role | CPU | RAM | GPU |
|---|---|---|---|---|
| Node 1 (Signal Engine) | Data ingestion, Greeks calc, trade execution, development | AMD 64-core | 192 GB | 1× RTX 3090 (24 GB) |
| Node 2 (Intelligence Hub) | LLM reasoning, sentiment analysis, trade approval | AMD 64-core | 192 GB | 2× RTX 3090 NVLinked (48 GB) |
Local LLM vs. Cloud LLM
Comprehensive comparison across five critical dimensions
3.1 Latency
Latency is the most operationally critical dimension for a trading system. Cloud LLM APIs introduce network round-trip latency that is fundamentally unavoidable. Benchmarks show that cloud API calls to GPT-4 class models introduce a Time to First Token (TTFT) of approximately 500 ms to 2,000 ms under typical conditions. A local LLM on the same private network with a 10 GbE direct-attach connection contributes only ~0.1–0.5 ms of network overhead.
3.2 Cost Analysis
Cloud LLM pricing is token-based and scales linearly with query volume. A trading bot making 50 LLM calls per day (2,000-token prompts, 500-token responses) costs approximately $0.675/day with GPT-4.1, or ~$170/year. Expanded monitoring or overnight analysis can push this into thousands annually. The local LLM has a marginal cost of zero per query.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Est. Daily Cost |
|---|---|---|---|
| GPT-4.1 (OpenAI) | $3.00 | $12.00 | ~$0.675 |
| GPT-4o Mini | $0.15 | $0.60 | ~$0.034 |
| Claude Opus 4.5 | $5.00 | $25.00 | ~$1.25 |
| Gemini 1.5 Flash | $0.08 | $0.30 | ~$0.018 |
| Local Llama 4 70B (Q4) | $0.00 | $0.00 | $0.00 |
3.3 Data Privacy & Regulatory Security
When a trading bot sends market data, position information, or strategy logic to a cloud LLM API, that data traverses third-party infrastructure. This creates three categories of risk:
3.4 Summary Comparison
| Dimension | Local LLM | Cloud LLM |
|---|---|---|
| Inference Latency | 1–5s (no network overhead) | 0.5–2s + network round-trip |
| Cost at Scale | Near-zero marginal cost | $170–$2,000+/year |
| Data Privacy | Complete — stays on-network | Sent to 3rd-party infra |
| Regulatory Risk | Minimal | Moderate to high |
| Uptime Dependency | Self-controlled | Dependent on provider SLA |
| Model Capability | Competitive for trading tasks | Marginally superior (frontier) |
| Setup Complexity | High (hardware, software) | Low (API key, HTTP calls) |
| Customization | Full (fine-tuning, RAG) | Limited (prompt only) |
Cost Calculator
Adjust your trading workload parameters to compare cloud API costs against local electricity costs in real time
Number of LLM calls per trading day
Prompt size (context + signal data)
Response size (decision + reasoning)
Cost per kWh (US avg: $0.12)
| Provider | Daily | Monthly | Annual | vs. Local |
|---|---|---|---|---|
| GPT-4.1 | $0.60 | $18.25 | $219.00 | +$11.69 |
| GPT-4o | $0.50 | $15.21 | $182.50 | $-24.81 |
| GPT-4o Mini | $0.03 | $0.91 | $10.95 | $-196.36 |
| Claude Opus 4.5 | $1.13 | $34.22 | $410.63 | +$203.31 |
| Claude Sonnet 4.5 | $0.23 | $6.84 | $82.13 | $-125.19 |
| Gemini 1.5 Pro | $0.25 | $7.60 | $91.25 | $-116.06 |
| Gemini 1.5 Flash | $0.01 | $0.46 | $5.47 | $-201.84 |
| DeepSeek API | $0.02 | $0.64 | $7.67 | $-199.65 |
| Local (Electricity only) | $0.57 | $17.28 | $207.31 | — |
Multi-Model Architecture
The case for specialized agents over a single monolithic LLM
A single monolithic LLM is suboptimal for a trading system because the tasks required span a wide range of cognitive demands. Real-time sentiment classification requires speed and domain vocabulary; strategic trade approval requires deep contextual reasoning. These demands are in tension. Running a 70B model for every task — including simple ones — wastes compute and increases latency unnecessarily.
The multi-agent architecture mirrors how sophisticated trading operations actually function. Real trading desks employ specialists: a news analyst, a quantitative risk manager, a senior portfolio manager who makes final decisions. Replicating this structure in software produces more robust, interpretable, and auditable outcomes.
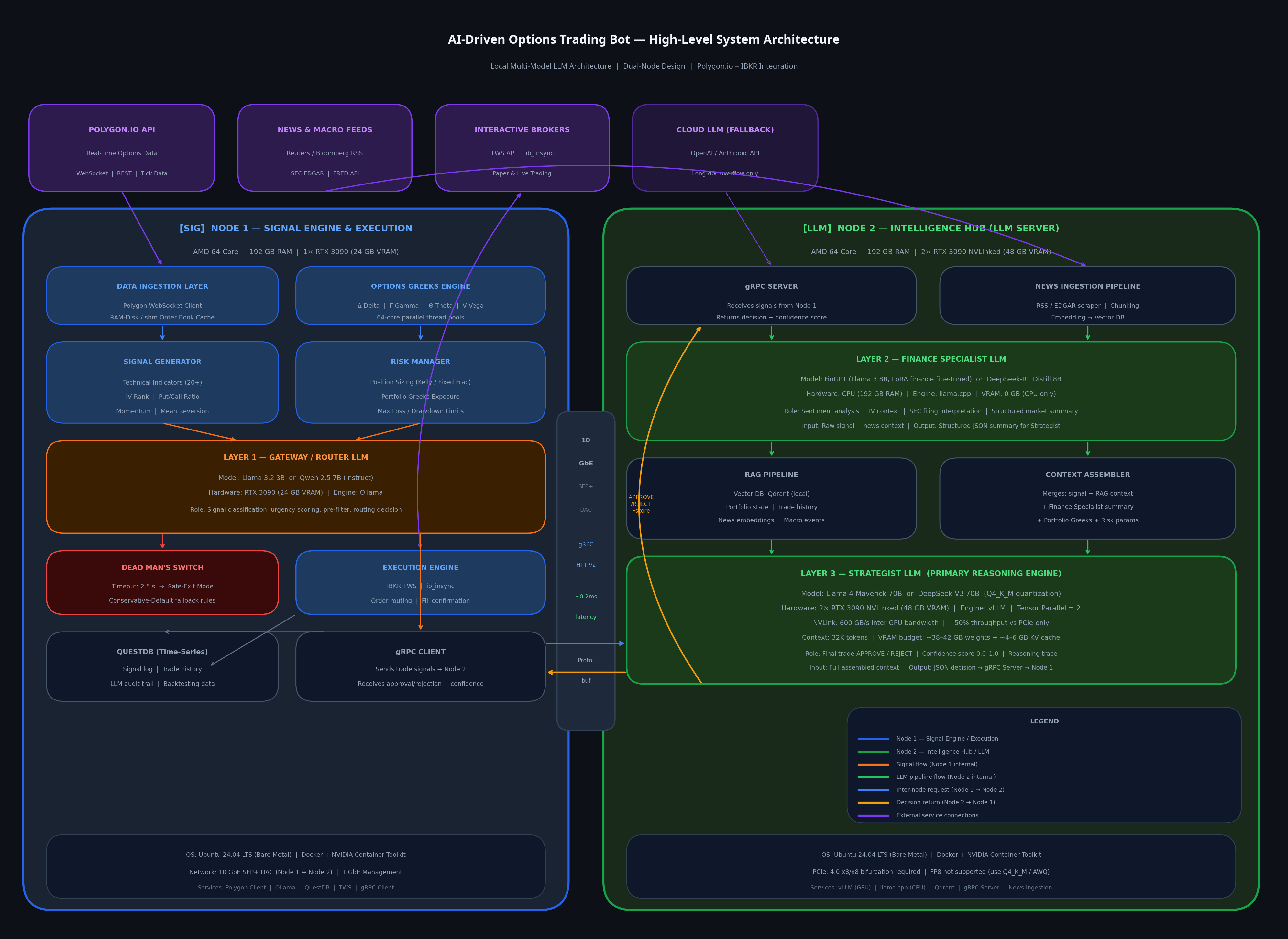
Receives incoming signals from Node 1, classifies query type, assesses urgency, routes to the appropriate specialist. Performs basic sanity checks: is the signal within expected parameters? Is the market open? Has a similar trade been executed recently?
Speed-optimized — acts as traffic controller and pre-filter, preventing larger models from being invoked unnecessarily.
Handles domain-specific tasks: interpreting options chain data, analyzing sentiment from news and SEC filings, calculating implied volatility context, and generating structured summaries of market conditions relevant to the trade signal.
Runs on CPU using 192 GB system RAM — preserves all GPU VRAM exclusively for the Strategist.
Receives pre-processed context from the Finance Specialist and routing metadata from the Gateway. Makes the final trade approval or rejection decision with a confidence score (0.0–1.0). Has access to full portfolio state, risk parameters, and recent trade history via RAG.
Invoked only when the Gateway determines a trade signal has passed initial screening — minimizing unnecessary inference cycles.
4.1 RAG Pipeline
Retrieval-Augmented Generation (RAG) allows the LLM to access current, structured information without requiring model retraining. The RAG system uses a local vector database (Qdrant) to store and retrieve embeddings. When the Strategist is invoked, the RAG pipeline retrieves the most relevant context and injects it into the prompt.
Model Selection
Recommended candidates for each layer of the agent hierarchy
| Model | Parameters | VRAM (Q4) | Recommended Role |
|---|---|---|---|
| Llama 3.2 3B | 3B | ~2 GB | Gateway (Node 1 RTX 3090) |
| Qwen 2.5 7B | 7B | ~4.5 GB | Gateway (Node 1 RTX 3090) |
| FinGPT (Llama 3 8B) | 8B | ~5 GB (CPU) | Finance Specialist (CPU) |
| DeepSeek-R1 Distill 8B | 8B | ~5 GB (CPU) | Finance Specialist (CPU) |
| Llama 4 Maverick 70B | 70B | ~38–42 GB | Strategist (Dual 3090 NVLink) |
| DeepSeek-V3 70B | 70B | ~38–42 GB | Strategist (Dual 3090 NVLink) |
Interactive Model Comparison
Explore benchmarks, trade-offs, and specs for every recommended model — select a layer and model to compare
- Llama 3.2 3B
- Qwen 2.5 7B
- Mistral 7B
| Model | Params | VRAM | Speed | License |
|---|---|---|---|---|
| Llama 3.2 3B★ | 3B | ~2 GB | ~800–1,200 | Llama |
| Qwen 2.5 7B | 7B | ~4.5 GB | ~400–600 | Qwen |
| Mistral 7B | 7B | ~4.5 GB | ~380–550 | Apache |
Llama 3.2 3B Instruct
Ultra-lightweight model optimized for fast classification and routing. Ideal as a gateway that must respond in under 500ms. Strong instruction-following for structured JSON output.
- Extremely fast inference
- Minimal VRAM footprint
- Strong JSON/structured output
- Low power draw
- Limited complex reasoning
- Weaker financial domain knowledge
- Small context window for complex prompts
Build Your Stack
Select one model per layer to see live VRAM budget, combined latency estimates, and a ready-to-run deployment script
Runs on Node 1 (single RTX 3090, 24 GB). Classifies incoming signals, filters noise, routes to specialist. Must respond in < 500ms.
Best choice for high-frequency signal classification. Leaves 21+ GB VRAM free on Node 1 for other workloads.
Gateway and Specialist run in parallel — the longer of the two determines the combined phase latency. Strategist waits for both before generating a decision.
Specialist runs on CPU — no VRAM consumed. 2 GB overhead per node reserved for CUDA/vLLM runtime.
Inference Engine Selection
vLLM vs. llama.cpp — when to use each
--tensor-parallel 2 to distribute across both NVLinked RTX 3090s. Use llama.cpp on Node 2 CPU for the Finance Specialist (8B model). Use Ollama (wrapping llama.cpp) on Node 1 for the Gateway (3B–7B model).VRAM Budget & Hardware Considerations
Node 2 VRAM Budget (48 GB total)
| Component | VRAM Allocation | Notes |
|---|---|---|
| Llama 4 70B (Q4_K_M) model weights | ~38–40 GB | Primary model weights across both GPUs |
| KV Cache (32K context window) | ~4–6 GB | Sufficient for full trade analysis prompts |
| vLLM overhead & CUDA buffers | ~1–2 GB | Runtime overhead |
| Total | ~43–48 GB | Tight but workable — limit context to 32K tokens |
Inter-Node Communication & Latency
The two nodes should be connected via a 10 GbE SFP+ Direct Attach Cable (DAC). The communication protocol should use gRPC rather than REST — gRPC uses HTTP/2 and Protocol Buffers, reducing inter-service latency by up to 60% for structured data payloads.
Estimated Round-Trip Latency
| Step | Estimated Latency |
|---|---|
| Node 1 generates trade signal | < 1 ms |
| Signal transmitted to Node 2 (10 GbE) | 0.1 – 0.3 ms |
| Gateway model routes request | 200 – 500 ms |
| Finance Specialist processes context | 500 – 1,500 ms |
| Strategist generates decision | 1,000 – 5,000 ms |
| Decision transmitted back to Node 1 | 0.1 – 0.3 ms |
| Node 1 executes trade via IBKR API | 50 – 200 ms |
| Total round-trip | ~2 – 7 seconds |
Safety, Risk Controls & Dead Man's Switch
Node 1 maintains a timeout counter for every LLM request sent to Node 2. If Node 2 fails to respond within 2.5–3 seconds, Node 1 automatically falls back to one of two pre-programmed behaviors:
The LLM should never have direct authority to size positions. Position sizing remains under deterministic risk management logic on Node 1. The LLM provides only a binary approval/rejection signal plus a confidence score (0.0–1.0).
Every LLM call — full prompt, model response, routing decision, and final trade outcome — should be logged to QuestDB (time-series database). Serves backtesting validation, regulatory compliance, and model performance evaluation.
API Integration
Polygon.io and Interactive Brokers TWS
System Architecture Diagram
High-level dual-node design with data flows and integration points
Hardware Upgrade Roadmap
When to upgrade, what to buy, and how to plan your path from dual RTX 3090 to future hardware
These are the specific, measurable conditions that should trigger an upgrade evaluation. ACT triggers require immediate action. PLAN triggers mean begin budgeting and evaluating options. WATCH triggers mean monitor the metric monthly. Click any trigger to expand details.
LLM Training & Configuration Guide
Layer-by-layer training data recommendations, LoRA/QLoRA hyperparameters calibrated to your RTX 3090 hardware, data sourcing strategies, quality filtering pipelines, and evaluation frameworks for each agent layer.
Core Principle: Precision Over Volume
A carefully curated dataset of 5,000–20,000 high-quality, domain-specific examples will outperform a noisy dataset of 500,000 scraped documents. FinLora (2025) demonstrated that LoRA fine-tuning on financial datasets achieves performance comparable to full fine-tuning while requiring only 1% of trainable parameters.
Signal classifier and router. Receives raw signals from Node 1, classifies by type/urgency, filters noise, routes to Specialist.
Dataset Composition
Recommended % split by category
Category Volume Distribution
Percentage of total training dataset per category
Training Data Categories — Click to Expand
Dataset Builder
Track your data collection progress for each LLM layer. Check off sources as you collect them. Progress is saved automatically in your browser. Export a summary report at any time.
Weighted readiness score (critical items count 3×)
11 Critical Gaps Detected
The following critical data sources are not yet collected. Training without them will significantly degrade model performance.
+ 5 more critical items…